Did you know there’s now a hash table whose access time can stay constant on average — and only logarithmic in the worst case — no matter how close it is to being completely full?
That claim, which overturns a belief dating back to Andrew Yao’s 1985 Uniform Hashing is Optimal conjecture, is proven in Optimal Bounds for Open Addressing Without Reordering (Jan 2025) by Andrew Krapivin, Martín Farach-Colton and William Kuszmaul. Their open-addressed design (nick-named funnel hashing) achieves three key bounds when the table is 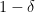

- Amortized expected probes:
— average queries run in fixed time, independent of fullness.
- Worst-case expected probes (non-greedy strategy):
, beating Yao’s linear-in-
lower bound by an exponential factor.
- Tight bound for **greedy strategies:** they exhibit a scheme with
worst-case expected cost and prove that no greedy algorithm can do asymptotically better.
In practical terms, even if your hash table is 99.9 % full (

The work also supplies a constant-time insertion/lookup on average, irrespective of load. That constant bound surprised even specialists: earlier proofs showed 
These results matter because open-addressed tables back some of the most latency-sensitive components in systems code: language runtimes, kernel symbol tables, in-memory DB indexes, even GPU hash-based acceleration. Replacing linear-probe or uniform-probe tables with an 
If you want the full technical story, the paper is open access on arXiv:
Optimal Bounds for Open Addressing Without Reordering
For a lively narrative of how an undergraduate stumbled into dismantling four decades of consensus, Quanta Magazine captured the back-story in their recent feature.
The upshot: twenty-odd pages of analysis have redrawn the map for one of computing’s oldest data structures, and any code hitting the performance wall at high table-load now has a fresh avenue for speed-ups.