Meta AI has released Code Llama, a family of large language models for code that establishes a new state-of-the-art for open-source models on code generation benchmarks.
Built off of Meta’s Llama 2 foundation models, Code Llama comes in three sizes – 7B, 13B, and 34B parameters – and three main variants: Code Llama, Code Llama-Python, and Code Llama-Instruct.
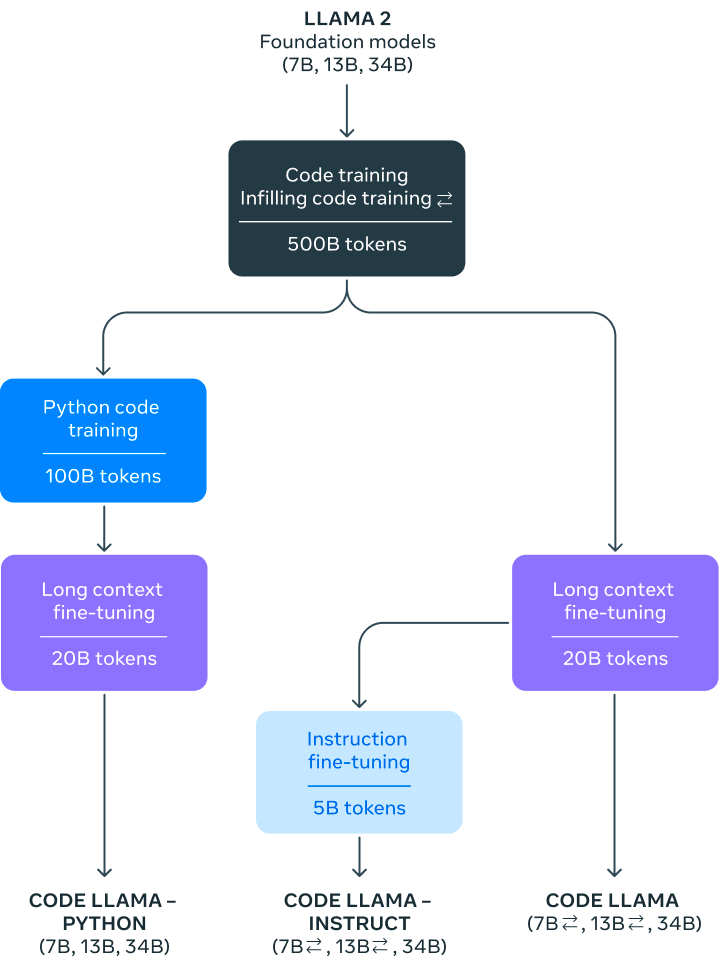
Training
The Code Llama training and fine tunig can be ssumarized as:
- Initialization: The Code Llama models start from the weights of the Llama 2 foundation models, which were pretrained on 2 trillion tokens of text and code data.
- Code Training: The base Llama 2 models are trained on an additional 500 billion tokens from a code-heavy dataset, mainly sourced from public code repositories. This specializes them for code tasks.
- Infilling Training: The 7B and 13B Code Llama models are trained with a multitask objective that includes infilling masked spans of code, enabling applications like autocompletion.
- Long Context Fine-Tuning: All models undergo additional fine-tuning to handle contexts up to 100,000 tokens, by modifying the positional embeddings.
- Python Specialization: The Code Llama – Python variants are further specialized by training on 100 billion tokens of mostly Python code.
- Instruction Fine-Tuning: Finally, the Code Llama – Instruct models are fine-tuned on a mix of human instructions and machine-generated self-supervision to improve safety, helpfulness and truthfulness.
Key Achievements
The 34B Code Llama model achieves a score of 48.8% on the HumanEval benchmark for generating code from natural language descriptions. This is the highest score among publicly available models, surpassing scores from models like PaLM Coder (36%) or GPT-3.5 (ChatGPT – 48.1%).
On the MBPP benchmark, Code Llama 34B reaches 55% pass@1 score, again the top score among open models. The multi-lingual version, Code Llama-Instruct 34B, achieves state-of-the-art pass@1 scores among public models on 6 programming languages in the MultiPL-E benchmark.
Code Llama also demonstrates an ability to handle long input contexts up to 100,000 tokens, a capability that could unlock reasoning over entire code repositories. The smaller 7B and 13B versions additionally support infilling text generation.

Unnatural models
For comparison purposes, Meta also finetuned Code Llama – Python 34B on 15,000 unnatural instructions similarly to Honovich et al. (2023). Meta did not release this model, but observed clear improvements on HumanEval and MBPP are indicative of the improvements that can be reached with a small set of high-quality coding data.
An unnatural model is a large language model that has been fine-tuned on unnatural data, which is data that is artificially generated specifically to improve the model’s performance on certain tasks.
The key characteristics of unnatural data are:
- It is not written by humans for natural communication purposes.
- It is algorithmically generated, often using the model itself or another model.
- It follows very specific patterns or templates tailored towards getting high scores on benchmark tasks.
The goal of using unnatural data is to rapidly improve the model’s skills in certain domains like programming, without the need for expensive human labeling or annotation. However, models fine-tuned this way can lose capabilities in general language understanding.
Unnatural fine-tuning is controversial because the data is not representative of natural language, and optimizing purely for benchmarks may result in peculiar behaviors. But it remains an active area of research for quickly conditioning models for new tasks.
Implications
The Code Llama family of models open up new possibilities for AI assistants, auto-complete, and synthesis tools used by software developers. By releasing Code Llama under an quasi open-source license, Meta aims to spur advances in AI for programming.
The model’s strong performance on code generation tasks could lead to more fluent coding workflows integrated into IDEs and other developer tools. Code Llama’s multi-lingual capabilities can broaden the scope of languages supported.
Handling long contexts can potentially enable summarizing or retrieving information across entire codebases. This could aid bug detection, documentation, and navigating large legacy codebases.