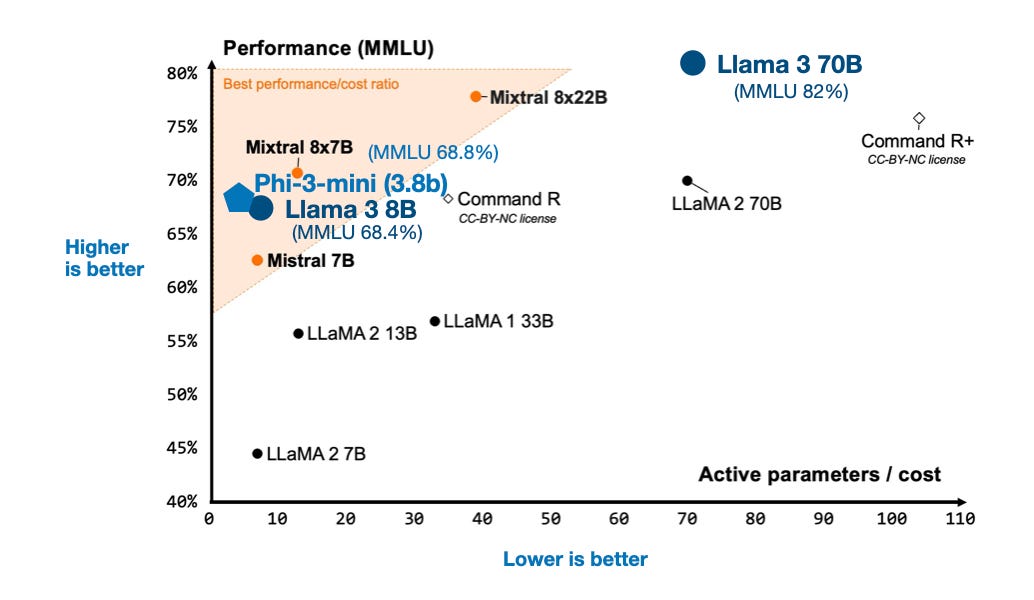
April 2024 marks a significant month in the field of large language models (LLMs) with the release of four major open-source models: 8x22B Mixtral, Meta AI’s Llama 3, Microsoft’s Phi-3, and Apple’s OpenELM. These models, built on transformer architecture, showcase advancements in mixture-of-experts (MoE) models, increased vocabulary sizes, and efficient language model families designed for mobile devices. Mixtral introduces an 8x22B MoE model under an Apache 2.0 license, emphasizing a low active-parameter count for computational efficiency. Llama 3, with its 8B and 70B variants, demonstrates significant performance improvements due to a larger training dataset of 15 trillion tokens and the use of both proximal policy optimization (PPO) and direct preference optimization (DPO) for instruction finetuning. Phi-3, despite being trained on fewer tokens, outperforms Llama 3’s smaller model through dataset quality, hinting at the importance of data curation. OpenELM by Apple focuses on small, efficient models for mobile deployment, introducing novel architecture tweaks like layer-wise scaling strategies.
In addition to these developments, there’s a plethora of research papers published in April, covering topics from Kolmogorov–Arnold Networks to teaching LLMs to utilize information retrieval effectively. This surge in LLM research not only demonstrates the rapid advancements in the field but also the growing interest in understanding and improving these complex models for practical applications.
Read more…