Recent advancements in large language models like GPT-3 and GPT-4 have demonstrated remarkable capabilities in logical reasoning and mathematical tasks. This has sparked debate around whether we are close to achieving artificial general intelligence (AGI) simply by continually scaling up next-token prediction models.
A new theoretical study from researcher Eran Malach provides insight into why auto-regressive next-token prediction results in such capable models. Malach shows that even simple linear models trained to predict the next token can approximate any efficiently computable function, given the right training data.
The key is using a technique called chain-of-thought (CoT), where the model is prompted to explain its reasoning step-by-step before outputting a final answer. This allows the simple model to receive supervision on intermediate steps of a complex computation.
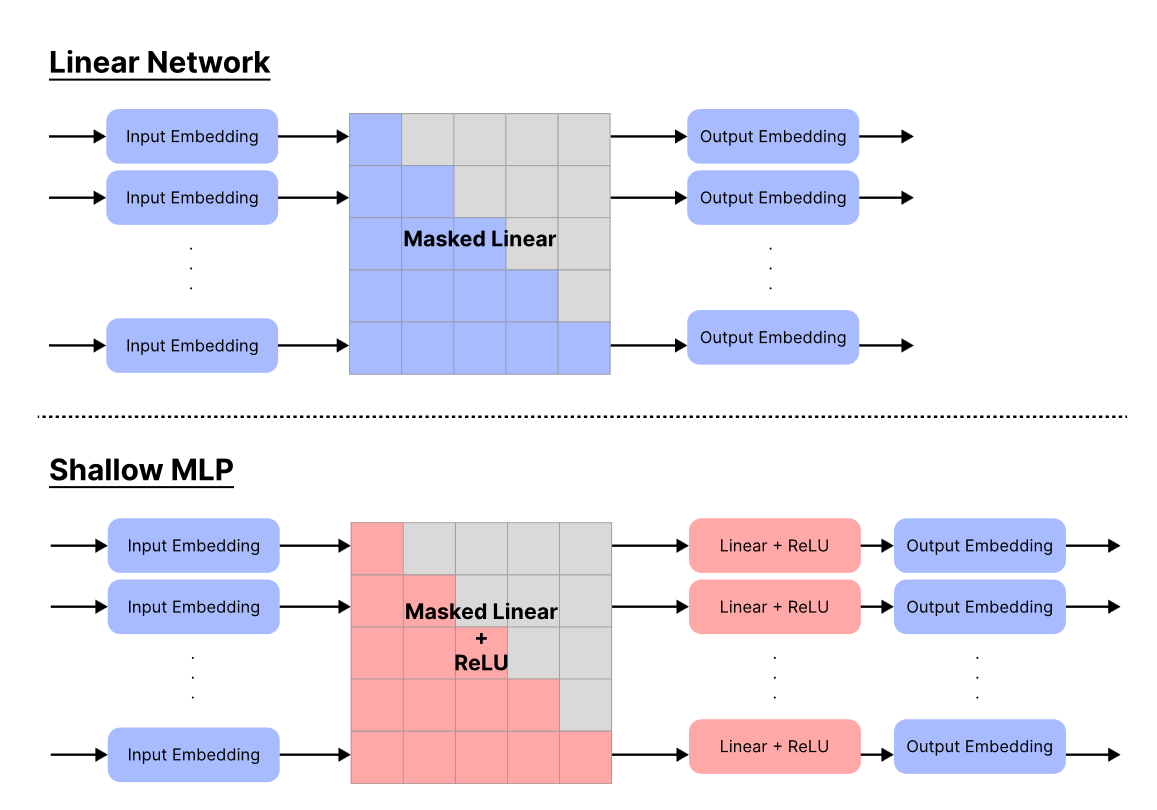
Malach introduces a theoretical framework to analyze auto-regressive learning and proves that linear next-token predictors, when trained on CoT data, can emulate arbitrary Turing machines. This result holds even for simple linear models, whereas typically linear models have limited expressive power.

Through experiments, Malach demonstrates that a linear model trained on a story generation dataset can produce reasonably coherent stories. Additionally, a small 775M parameter MLP network, when trained on CoT multiplication data, matches the performance of a 7B parameter transformer on 4-digit multiplication – even exceeding GPT-4.

The findings indicate much of the reasoning capacity of large language models stems from the nature of auto-regressive learning, rather than model scale or architecture. However, providing the lengthy intermediate supervision sequences required can be impractical. Malach introduces “length complexity” to measure this cost.
By studying auto-regressive learning theory, we gain insight into model capabilities and interpretability. Simple models can act as “universal learners” given suitable CoT data. However, further research is needed to understand how to efficiently provide such intermediate reasoning chains.