Optimizing Large Language Models (LLMs) to produce valid JSON or YAML outputs in line with specific schemas is crucial for various applications. A new optimization technique has been introduced that leverages a compressed finite state machine to enable constrained decoding, which is compatible with any regular expression. This method significantly outperforms traditional token-by-token decoding, reducing latency by up to 50% and increasing throughput by up to 150%. It even surpasses normal decoding speeds.
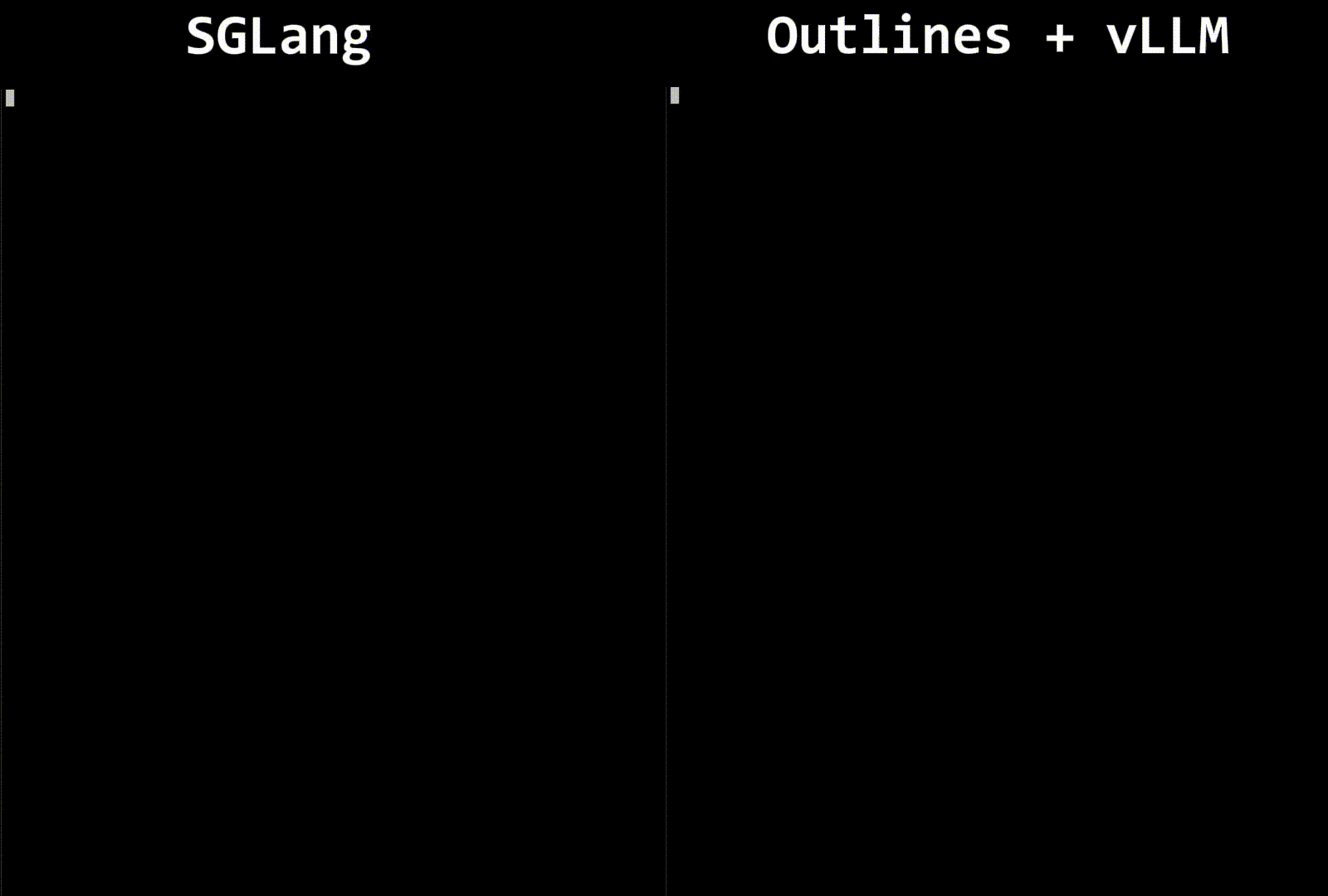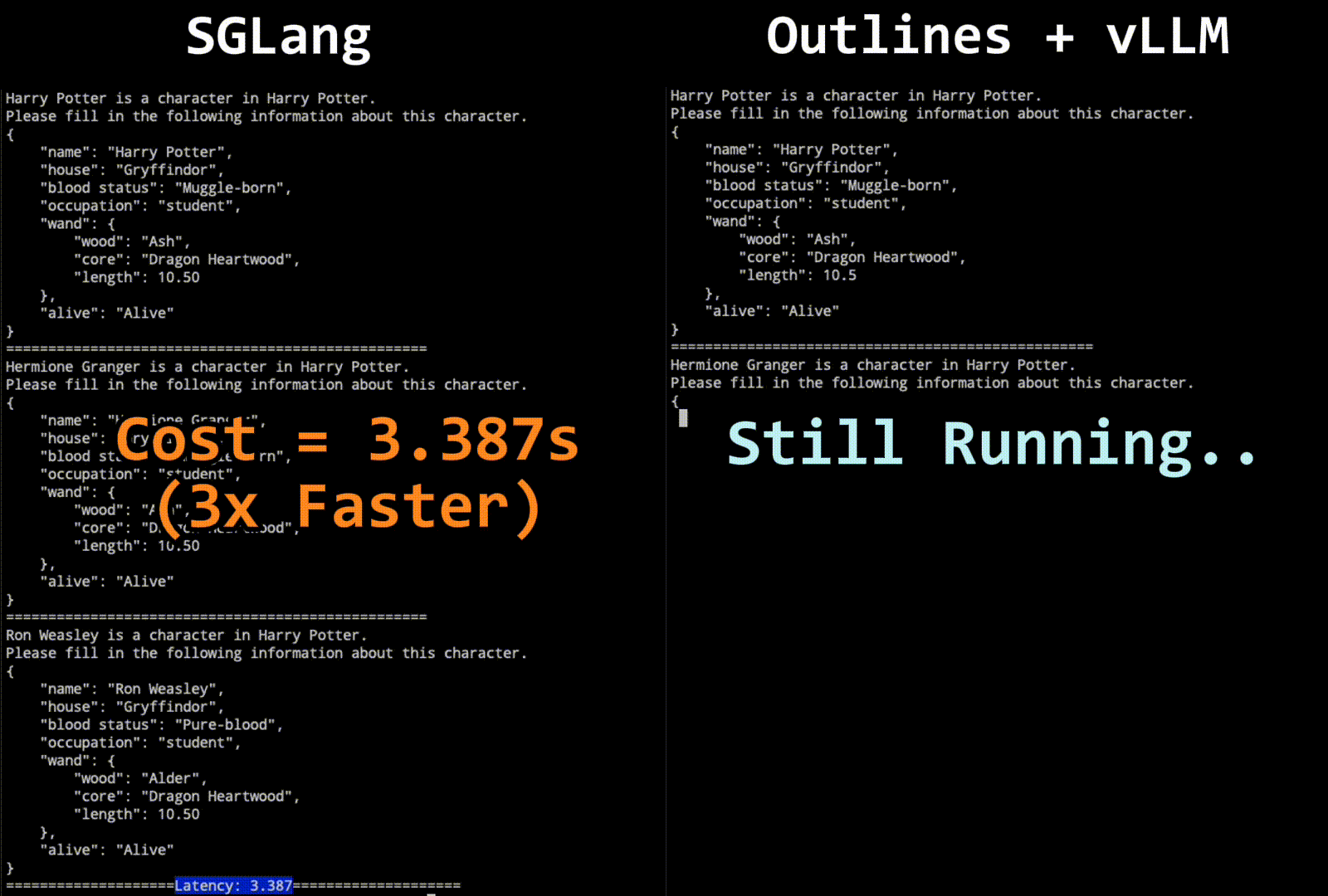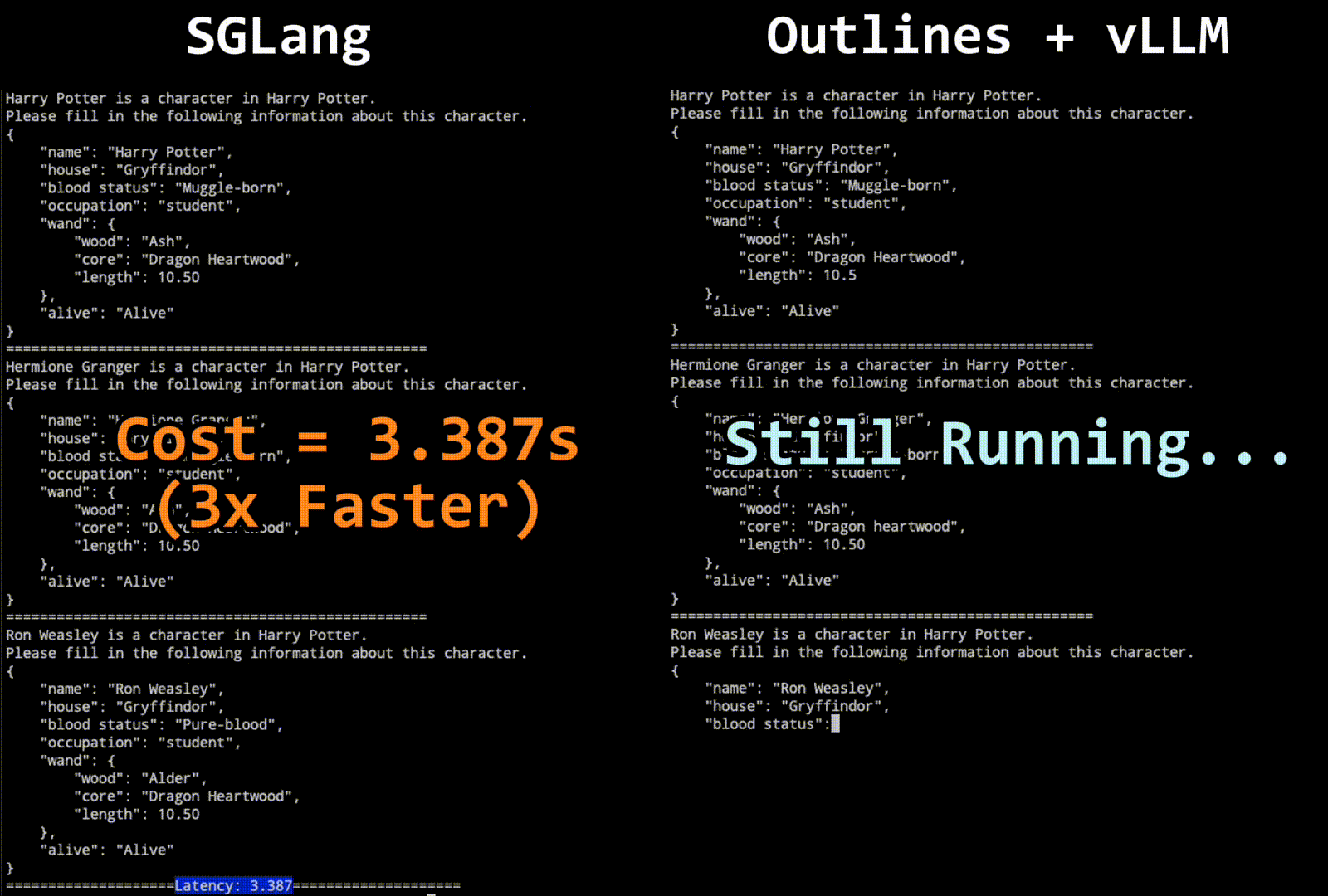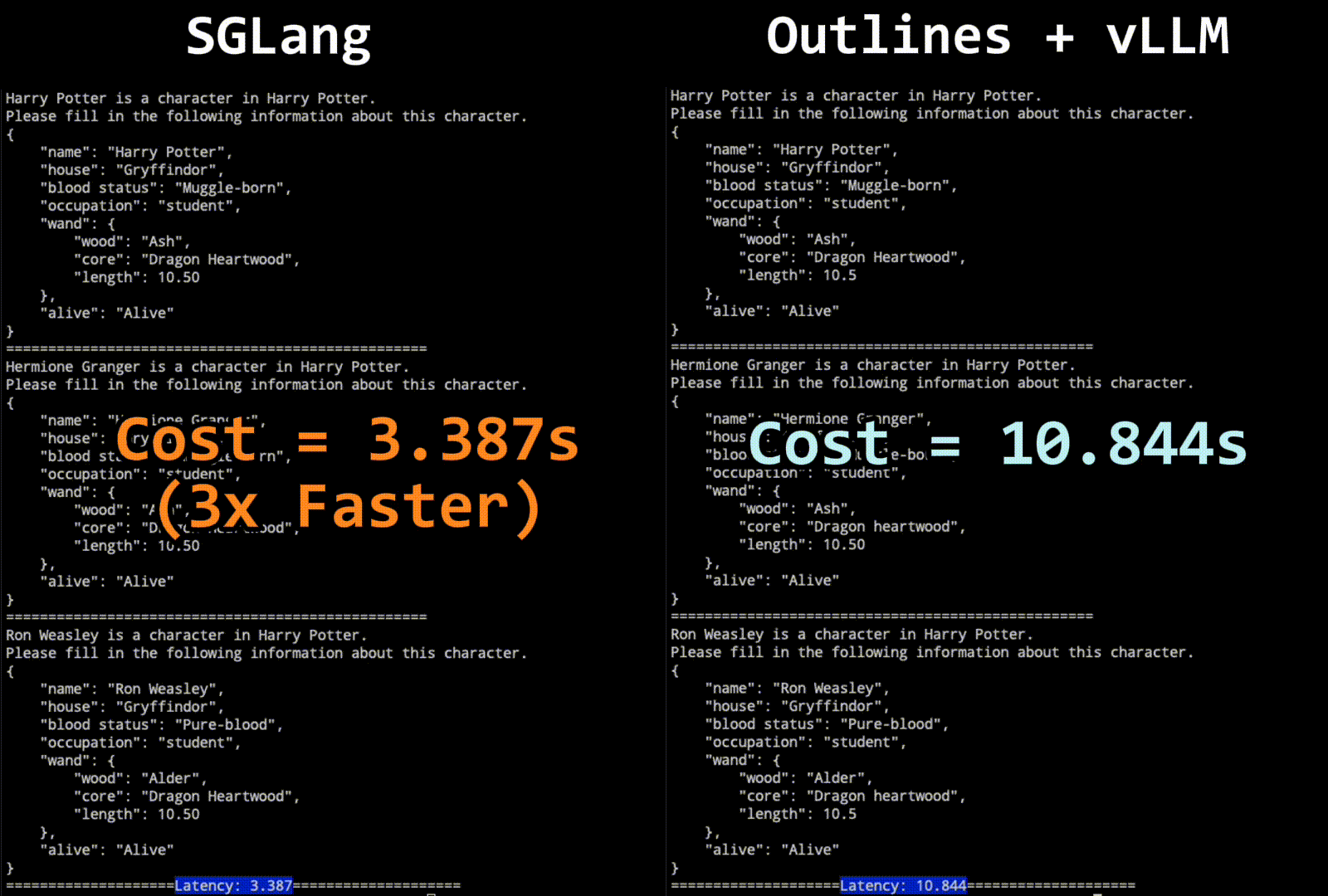
The technique combines the strengths of finite state machine-based and interleaved-based methods, allowing for multiple tokens to be decoded in a single step when possible. This jump-forward decoding algorithm predicts upcoming strings, compresses singular transition paths, and jumps to the next branching point, thus accelerating the decoding process.
Challenges with tokenization boundaries are addressed through a re-tokenization mechanism during the jump-forward phase, ensuring accurate and efficient decoding. Benchmark results demonstrate the superiority of this approach over existing systems, with significant improvements in speed and efficiency.
This feature has been successfully tested in production use cases, such as with Boson.ai, and has been applied to extract structured information from images using the vision language model LLaVA. Users can now access this feature in SGLang, and the benchmark code is available for reference.
Read more…