Researchers from UC San Diego and Meta AI have developed a new decoding method called Contrastive Decoding (CD) that improves reasoning abilities in large language models like LLaMA.
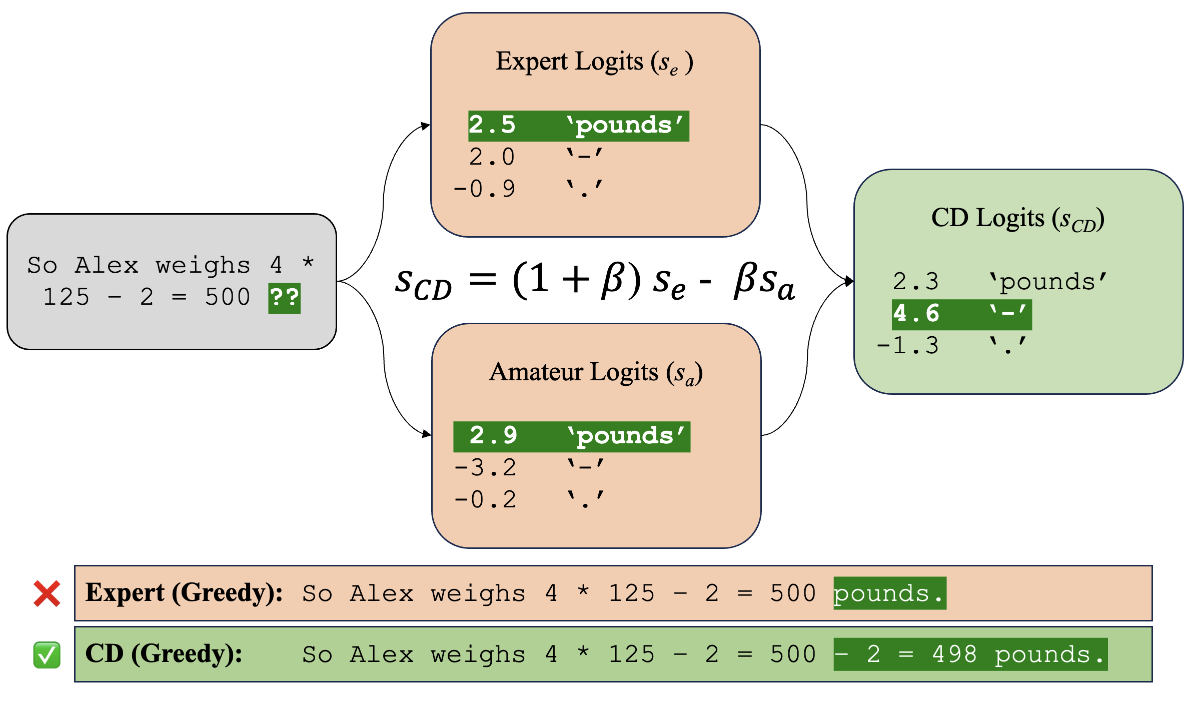
The method works by searching for text that maximizes the difference in likelihood between a stronger “expert” model and a weaker “amateur” model. This causes the expert model to avoid short, generic responses which the amateur can also generate.
In experiments, Contrastive Decoding improved performance of LLaMA models on math word problems, logical reasoning tasks, and common sense reasoning benchmarks. For example, it boosted LLaMA-65B’s accuracy on the GSM8K math dataset from 51% to 57%, outperforming even larger models like PaLM 540B.
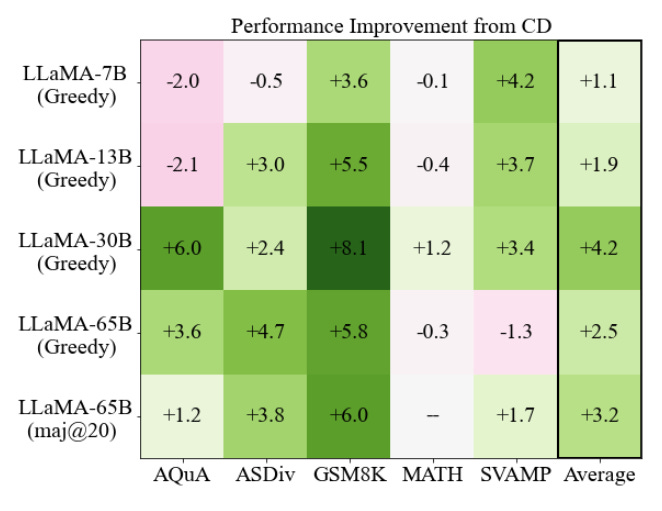
On the HellaSwag common sense reasoning dataset, Contrastive Decoding helped LLaMA-65B achieve 88% accuracy, surpassing results from GPT-3.5 and PaLM. The method improved performance across model sizes up to 65 billion parameters, suggesting it could benefit even larger future models.
The researchers posit Contrastive Decoding works by reducing “shortcuts” like copying parts of the input text, forcing models to generate more substantive reasoning chains. Analysis showed it resulted in fewer missing steps on math problems.
Contrastive Decoding could have significant implications for deploying AI systems. By boosting reasoning, it could make models more reliable for real-world applications like answering questions and generating explanations. The simple method requires no additional training, so it could easily be applied to existing models.
The work demonstrates Contrastive Decoding’s versatility as both a decoding method for text generation and a scoring function for selecting answers. It achieves strong results on both long-form reasoning tasks as well as multiple choice QA. The researchers propose it as a general technique to improve generation across different models and datasets.